DataTorch Patch 0.4.0 Notes
The Pipelines tab in the annotator has arrived.
DataTorch · January 28, 2025
Welcome to DataTorch 0.4.0, which comes with release of the Pipelines Tab in the annotator, allowing you to see real-time updates on the status of your pipelines run without needing to leave the annotator page.
We've also made some updates to the Python client, adding support for Python 3.12, as well as improvements to allow for smoother installation and programmatic uploading of files.
Pipelines Tab
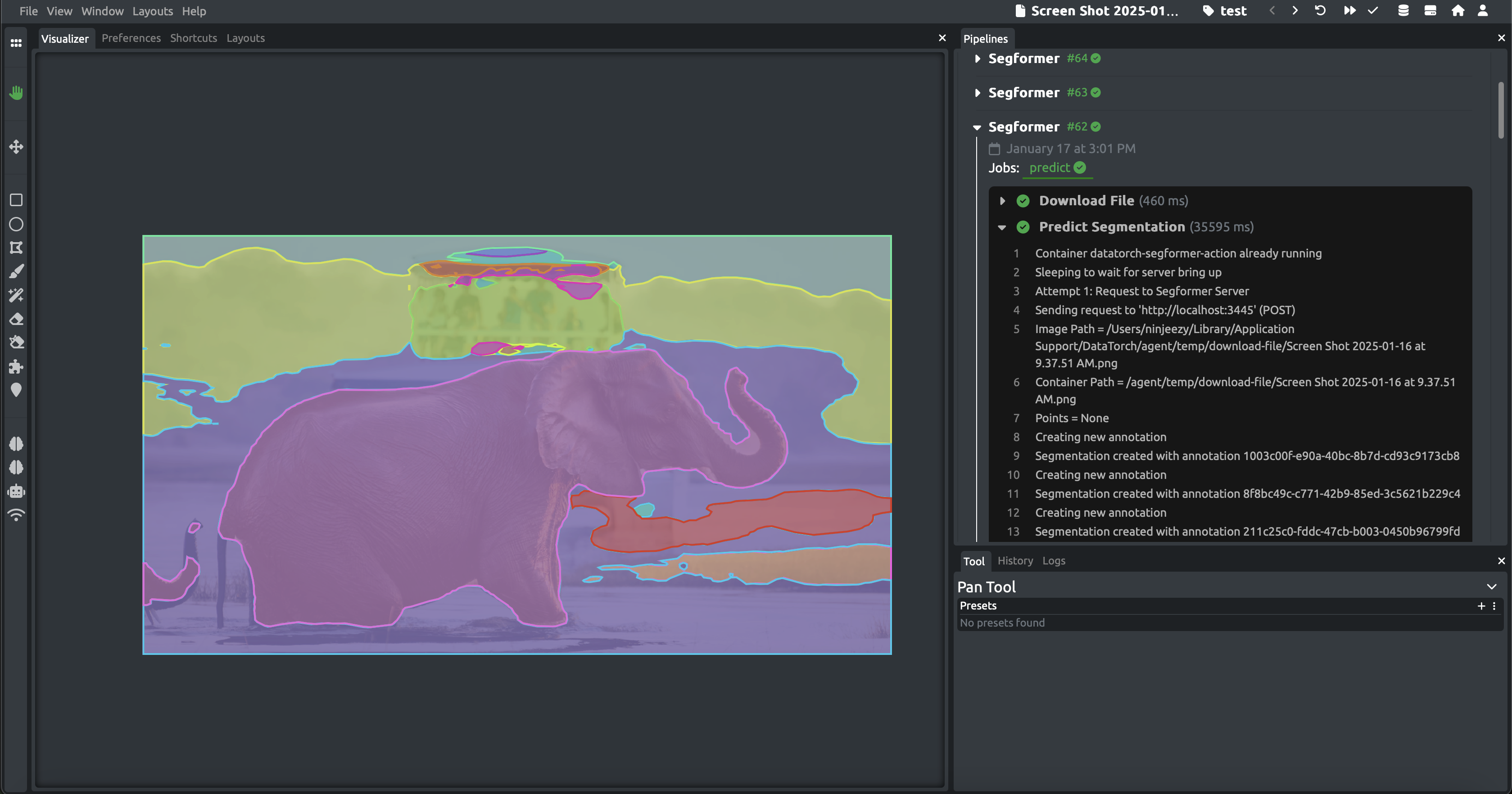
Power users of DataTorch have written pipelines with annotator triggers primarily to run their own models directly on the file being viewed in the browser. However, getting feedback on these pipelines has been a hassle, as users would have to go back into the Pipelines section of their project to see the logs of their actions, breaking workflow and adding complication.
To fix this, we are introducing the Pipelines Tab, a tab directly in the annotator that provides a real time update of each job that is being run in your project, showing the status and logs of each job and step.
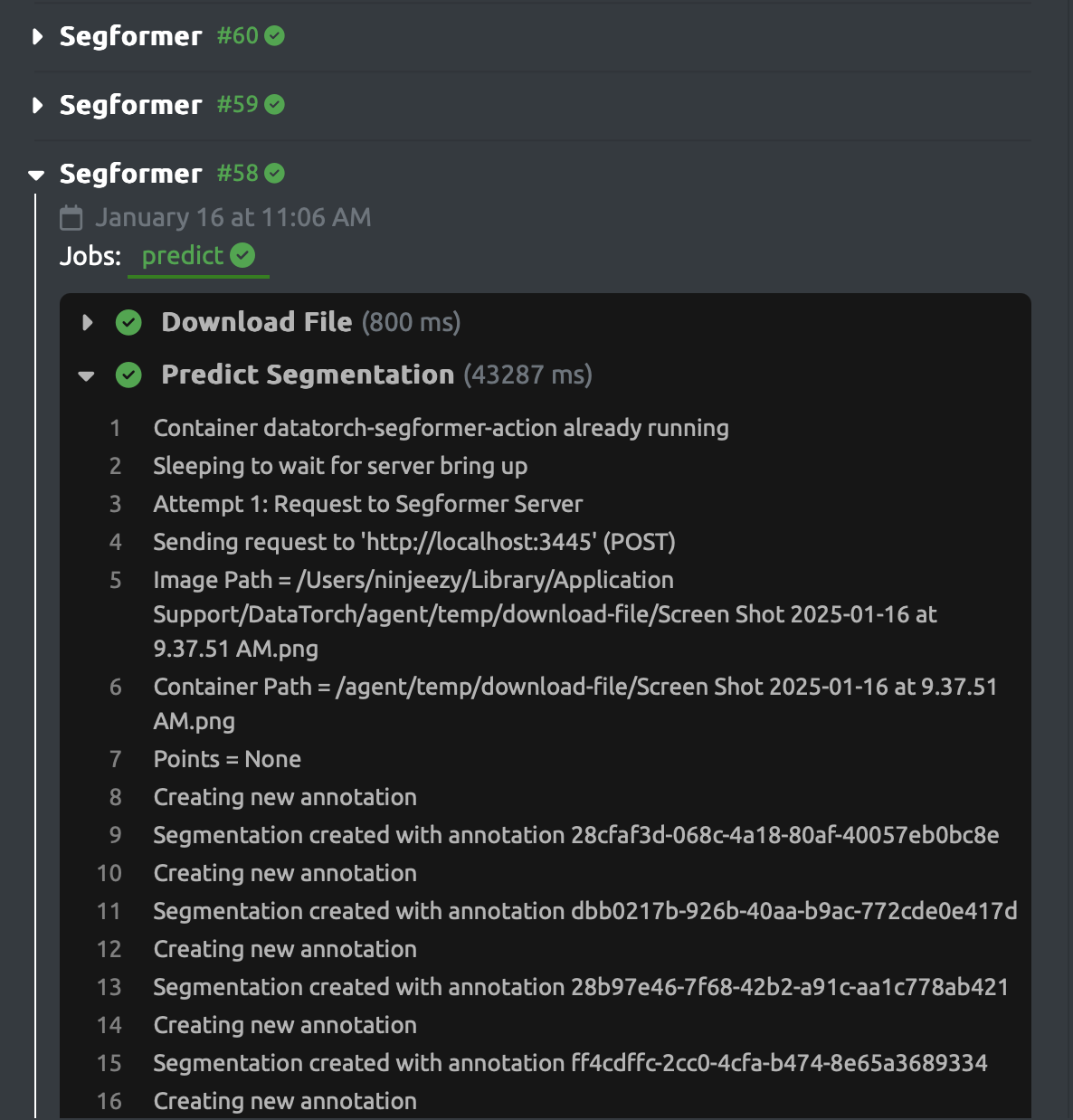
Now, users can enjoy real time feedback on the progress of their pipeine as soon as they press the trigger in the annotator, and resolve or debug issues in a far more streamlined manner than before. Give it a try with your next annotatorButton triggered pipeline!
Python Client
We've updated our Python client to support Python version 3.12 and dropped support for Python 3.8. Furthermore, we have expanded the upload functions in the API and CLI tool to make it easier to upload directly to your project programmatically.
Some key changes include:
- Introduction of the upload_to_filesource function to the API, meant to replace the upload_to_default_filesource function, allowing you to specify which storage and dataset you wish to upload files into:
def upload_to_filesource( self, project: Project, file: IO, storageId: str = None, storageFolderName:str = None, dataset: Dataset = None, **kwargs )
- Introduction of the upload option to the CLI, a wrapper around upload_to_filesource, letting you upload files and folders directly via CLI commands
- Example script in the Python repository (in the Examples folder) that demonstrates use of the upload_to_filesource function in a script:
import os import datatorch as dt api = dt.api.ApiClient("your-api-key") proj = api.project("user-name/project-name") dset = proj.dataset("data-set-name") folder_to_upload = "uploadme" upload_to_storage_id = "your-storage-id" # Get all the file names in the folder files = [ f for f in os.listdir(folder_to_upload) if os.path.isfile(os.path.join(folder_to_upload, f)) ] # Upload files to the selected storage and dataset using their IDs try: for file_name in files: file_path = os.path.join(folder_to_upload, file_name) with open(file_path, "rb") as file: api.upload_to_filesource( project=proj, file=file, storageId=upload_to_storage_id, storageFolderName=None, dataset=dset, ) except Exception as e: print(f"Error Uploading: {e}")
Bugfixes & QOL Changes
- Fixed typos on landing page
- Added better feedback for running pipelines in the annotator
- Added handling of uploading files of same name to cloud storages

© 2026 DataTorch. All rights reserved.